
With the rise of AI & ML within Life Sciences & Health, it’s become obvious that a key blocker to success is not the maturity of the AI tools and techniques but access to data in sufficient volume and quality for the AI & ML methods to analyse. In this blog we discuss some of the options for data sharing and implications for AI/ML model building.
Depending on the AI/ML model being developed, having access to a broad cohort of data from across the domain will be critical to ensure the necessary diversity, edge cases and breadth that will make the analysis successful with broad applicability.
Other “softer”, less technical factors will also become increasingly important going forward, including the broader ethics of AI [1] and the possible regulatory implications of using AI for health decisions. The need to solve these issues will become greater as the potential & impact for AI in life science is shown and validated through the applicability of the models to decision making.
Data sharing approaches
All this raises key questions as to what types of data sharing approaches are needed to allow AI & ML to work successfully. A number of options exist for making data accessible and we discuss these below and provide examples of them.
Publish the data into a domain specific public research platform based on the key data types and usage (chemistry & assay data, pharmacological, imaging) that supports direct submission e.g. PubChem, ChEMBL, Protein Data Bank (PDB), Cancer Imaging Archive. This provides good access given the structured nature of the data submission process and the ability to link to other related data (see Figure 1)
- We are reaping the benefits of these repositories and their ability to curate and structure data
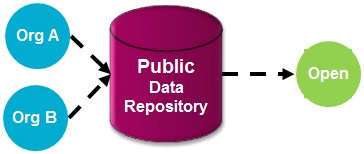
Figure 1
Publish the data into a broad domain agnostic public research repository (e.g. Figshare, Zenodo). This could include publishing to a journal or preprint server (e.g bioRxiv, chemRxiv) at the same time as the data submission.
- Ability to extract data & metadata from the submitted datafile depends a lot on the quality of the original submission and its structured nature (e.g. FAIR & use of appropriate data standards). Data wrangling & ingestion will be a key part of the interpretation process
- Not always an option for health data nor data with commercial or intellectual property sensitivity.
Patent applications could be considered part of this process but the extraction of data from patents is time consuming and not all data is published
Use a Trusted partner or data consortium:
- Establish a trusted partner or consortium/alliance model who will store the data and make it accessible according to agreed rules among the partners with rules on access both for the data depositors and also for data access & analysis in general. (See Figure 2)
Examples exist already in the Life Science and Health arena covering some key workflows and below are just some of them (by all means suggest others)
- Toxicity and Safety Data (e.g Lhasa Limited and IMI projects eTox & eTransafe)
- Genomics England and their embassy model for data access
- Transmart Foundation & eTriks for Translational data
- Open PHACTS
- Chemical Safety Library from Pistoia Alliance
- MedChemica for Matched Molecular Pairs (MMPs) database
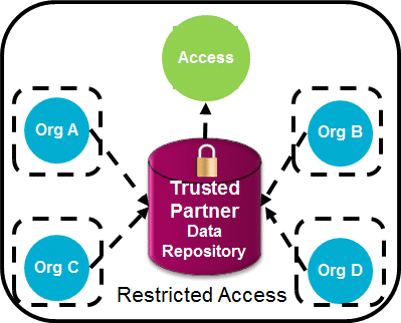 Figure 2 – Trusted Partner
Figure 2 – Trusted Partner
- Partners in the consortium model need to sign agreements
- Trusted partner needs to sign agreements and show their capability to preserve the data security and privacyFor instance, the trusted partner may be the only one to see each of the datasets while other organisations can only see their own data
- There may be provision for anonymised or aggregated data for all the members to access. This depends on the data domains and use cases for analysis
- It may take time to establish the legal agreements to allow the appropriate data sharing and there might be restrictions on what types of data can be shared (IP sensitive material, Personal information and other sensitive data)
Point to point data sharing
- A variation of the trusted partner model for when two organisations wish to share with each other
- There may be issues and restrictions with what data can be shared as with the trusted partner model. Do both share alike?
- One to one relationships can get complicated when other parties are brought in and legal agreements need to cover Merger & Acquisition (M&A) activity and other significant legal events.
- Technology solutions such as Blockchain could offer support for this approach and in the multi party data sharing described above
AI/ML Model Building Implications for data sharing scenarios
Building models across data from different organisations will be critical for where datasets from one organisation’s work are not sufficient to build a representative model that has broad applicability.
We will need to work on solutions that support privacy preserving data sharing that allows the models to be developed and refined and we discuss some of these below.
Each of these data sharing approaches have different implications for the AI/ML models that can be derived. The Open Minded Community is also looking into this.
Public data repository or publication
- For the public data repository or publication, then anyone can access the data and build models. The key here remains the quality and metadata associated with the datasets.
Trusted partner and Model Building
- The model needs to be built by the Trusted partner within the trusted environment. This is simplest approach to model building compared to the ones described later. It follows the model of Lhasa (See Figure 3)
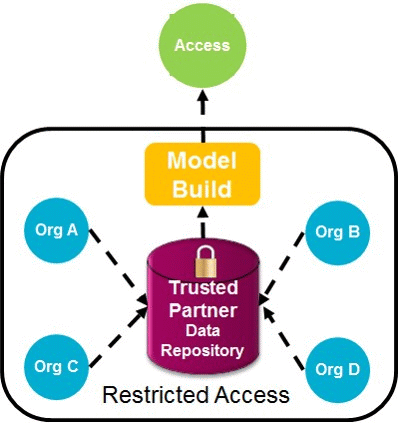
Figure 3 Trusted Partner Model Build
Privacy-preserving (Federated Model Building)
- An extension of the trusted partner model using a technical solution that takes the model-building process to the data in each of the locations/organisations that the data exists. [2] (See Figure 4)
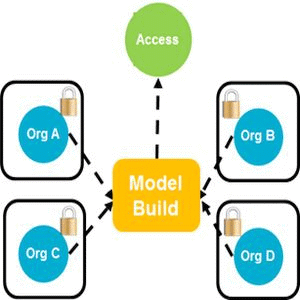
Figure 4 Federated Model Build
There has been much discussion about these approaches and various methods have been presented that take this a step further looking at the data access & privacy preserving techniques. Beyond the simple Cloud based approach described above, there is much research on taking this approach forward including these two examples:
- Differential privacy [4]
- One emerging approach operates on the principle of differential privacy. This is a statistical technique that aims to maximize the accuracy of the data while balancing the customers’ unique information. To help this, it optimizes models using a modified stochastic gradient descent — the iterative method for optimizing the objective functions in AI systems — that averages together multiple updates induced by training data examples (customer data), clips each of these updates, and adds noise to the final average.
- To prevent the memorization of rare & customer unique details, the different privacy technique works to ensure that two machine learning models are indistinguishable whether or not a customer’s data was used in their training.
- There remain limitations with high dimensional data using this differential privacy techniques and therefore other methods using generative neural networks are being investigated. We cover more of these approaches in a future blog on ‘Synthetic data’
- Homomorphic encryption of the data [3]
-
- This allows user data to be encrypted at source, protecting against unintended release of such data, while still being amenable to data processing & model build. This affords users better privacy – their data cannot be used arbitrarily – while allowing data processors & modelers to collect and use such data in cloud computing environments.
- This approach does introduce extra processing steps and so further work is required to improve performance for large datasets
-
We expect this to be expanded area of research over the coming years and look forward to tracking its process in the broad data domains as well as in Life Science & health where the ability for patients to control & give permission for the data access is growing.
Summary
Data is at the heart of AI & ML potential in Life Sciences and ‘no data no AI/ML’ remains a valid summary of our current situation. As an industry, getting access to broad datasets remains a challenge even though there are many excellent sources of publicly accessible data, these public datasets represent a fraction of the total data created in Life Science and Health. Being able to combine data from the public domain as well as data from private & restricted access datasets held within organisations should have a positive impact on the quality of AI/ML models in the future.
We present some examples of how the industry is sharing data to allow these models to encompass private data but also preserving the privacy of the data at the same time.
We can expect to see increased activity in this field both in terms of the techniques available but also in the available models that encompass this data.
Another outstanding issue is the nature of scientific publishing & the academic reward process since the published data sets tend to focus on the success stories while negative and unsuccessful experiments go under reported. This ‘dark data’ remains a challenge that we need to address in the future.
All of this also assumes that the data is published in a usable format with sufficient metadata, semantic links (including FAIR) to make it useful. A big ask, but we will cover that in a subsequent article on the role of metadata for AI & ML model building.
In our next article we will look at the role of synthetic data in model building as an emerging option and as a potential route for avoiding the need for data sharing (especially sensitive or personal data) as well as increasing the volume of potential data available for model training & development.
References
[1] Ethics and AI:
- Artificial intelligence as a medical device in radiology: ethical and regulatory issues in Europe and the United States August 2018 Insights into Imaging 9(5) DOI:10.1007/s13244-018-0645-y
- EU Ethics Guidelines for AI https://ec.europa.eu/digital-single-market/en/news/ethics-guidelines-trustworthy-ai
[2] Privacy Preserving Model Training
- Open Minded https://www.openmined.org/
- Open Minded White paper https://arxiv.org/abs/1811.04017
- https://arxiv.org/pdf/1703.00380.pdf
- https://www.oreilly.com/ideas/how-privacy-preserving-techniques-can-lead-to-more-robust-machine-learning-models
- https://www.oreilly.com/ideas/how-to-build-analytic-products-in-an-age-when-data-privacy-has-become-critical
[3] Homomorphic Encryption
- https://blog.cryptographyengineering.com/2012/01/02/very-casual-introduction-to-fully/
- https://medium.com/corti-ai/encrypt-your-machine-learning-12b113c879d6
[4] Privacy Preserving techniques
- https://www.turing.ac.uk/research/research-projects/evaluating-privacy-preserving-generative-models-wild
- Google Tensor Flow Privacy https://medium.com/tensorflow/introducing-tensorflow-privacy-learning-with-differential-privacy-for-training-data-b143c5e801b6
- Intel HE Transformer https://github.com/NervanaSystems/he-transformer
This article first appeared on Medium.
Acknowledgements: I would like to thank our AI CoE project members for the healthy discussion and contributions to this article. In addition, I thank Richard Shute for their insights and contributions to this article.
Top Photo by Markus Spiske on Unsplash
All other diagrams by Curlew Research CC SA NC