
This collaborative project was launched to create a bottom-up qualitative Natural Language Processing (NLP) Use Case Database, to allow NLP practitioners in pharma companies to share successes and failures with their peers. Narrowing down successful use case scenarios will lead to less experimentation and higher success rates for new NLP initiatives.

Why is this important?
Natural Language Processing offers great promise to improve efficiency and understanding of relationships and extract meaning from vast amounts of unstructured text. Pharma companies apply NLP methods in hopes of automation and insight generation. NLP experts have been investing significant resources in developing tools to address multiple business cases throughout the pharma industry in domains as varied as R&D, pharmacovigilance, and manufacturing, however, success seems very use case-specific.
Although Natural Language Processing algorithms have matured quite a bit during the past years, practical value for most NLP pilots tends to be poor, and very few NLP-driven projects are seen through to production. Exceptions are typically topics with good metadata quality, large training sets and willing business colleagues to verify results and a serendipitous combination of technical expertise and suitable use cases.
This type of knowledge is of value to share in a pre-competitive manner among Pistoia Alliance members. A simple database could contain characterization of use case, data characterization, pipelines & algorithms used, quality criteria, outcomes, and comments.
What will the project achieve?
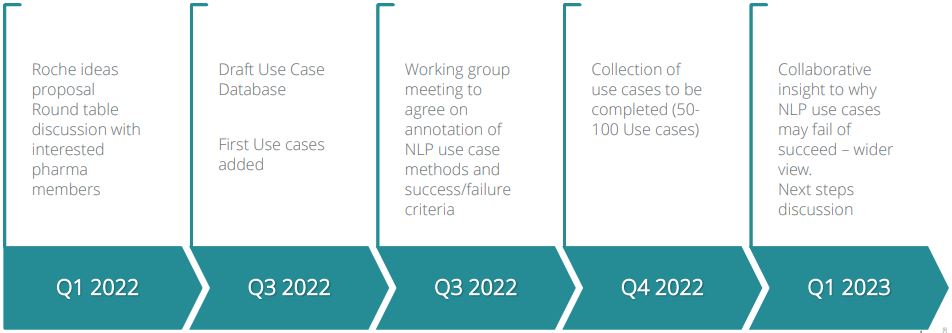
The team will deliver the following:
- A bottom-up qualitative NLP Success Failure Database with 50-100 Use cases
- Agreed annotations of NLP use case methods and success/failure criteria
- Collaborative insight into why NLP use cases may fail or succeed with an industry-wide view
Project Funders






